
新乡腾博tengbo9888官网,腾博官网入口网址,腾博官网弹簧有限公司
专注生产各类弹簧三十余年
全国服务热线 18530710992
专注生产各类弹簧三十余年
全国服务热线 18530710992
专注生产各类弹簧三十余年
全国服务热线 18530710992

18530710992
河南省辉县市学院路北段路西
Linpack HPC 是性能测试工具。LINPACK是线性系统软件包(Linear system package) 的缩写, 主要开始于 1974 年 4 月, 美国Argonne 国家实验室应用数学所主任 Jim Pool■◆★, 在一系列非正式的讨论会中评估,建立一套专门解线性系统问题之数学软件的可能性。

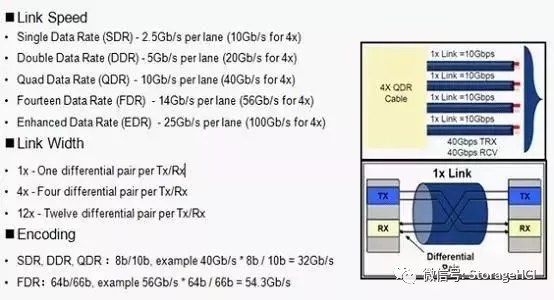
InfiniBand架构是一种支持多并发链接的“转换线缆”技术,InfiniBand技术不是用于一般网络连接的,它的主要设计目的是针对服务器端的连接问题的。因此,InfiniBand技术将会被应用于服务器与服务器(比如复制◆★,分布式工作等)■★◆◆■,服务器和存储设备(比如SAN和直接存储附件)以及服务器和网络之间(比如LAN,WANs和互联网)的通信。高性能计算HPC系统为什么要使用IB互联?主要原因是IB协议栈简单,处理效率高,管理简单★★■◆,对RDMA支持好,功耗低,时延低。
分布式文件系统的设计基于客户机/服务器模式。一个典型的网络可能包括多个供多用户访问的服务器★◆◆★■■。当前主流的分布式文件系统包括: Lustre★■◆、Hadoop、MogileFS、FreeNAS、FastDFS、NFS、OpenAFS、MooseFS、pNFS、以及GoogleFS等◆■★,其中Lustre、GPFS是HPC最主流的。
Linpack现在在国际上已经成为最流行的用于测试高性能计算机系统浮点性能的Benchmark。通过利用高性能计算机◆■■★,用高斯消元法求解N元一次稠密线性代数方程组的测试◆■,评价高性能计算机的浮点性能■★。
高性能计算(HPC) 指通常使用很多处理器(作为单个机器的一部分)或者某一集群中组织的几台计算机(作为单个计算资源操作)的计算系统和环境■◆★◆。高性能集群上运行的应用程序一般使用并行算法,把一个大的普通问题根据一定的规则分为许多小的子问题,在集群内的不同节点上进行计算◆★,而这些小问题的处理结果★■★,经过处理可合并为原问题的最终结果■★■。由于这些小问题的计算一般是可以并行完成的,从而可以缩短问题的处理时间。

TOP500 HPC系统中存储主要使用分布式文件系统,分布式文件系统(Distributed File System)可以有效解决数据的存储和管理难题: 将固定于某个地点的某个文件系统,扩展到任意多个地点/多个文件系统,众多的节点组成一个文件系统网络。每个节点可以分布在不同的地点,通过网络进行节点间的通信和数据传输★■■。人们在使用分布式文件系统时,无需关心数据是存储在哪个节点上、或者是从哪个节点从获取的,只需要像使用本地文件系统一样管理和存储文件系统中的数据。
HPC系统目前主流处理器是X86处理器★◆■,操作系统是linux 系统(包括Intel、AMD、NEC、Power、PowerPC、Sparc等)、构建方式采用刀片系统,互联网络使用IB和10GE◆■。
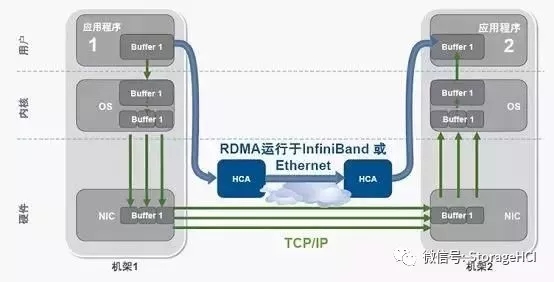
RDMA(Remote Direct Memory Access)技术全称远程直接数据存取,就是为了解决网络传输中服务器端数据处理的延迟而产生的◆◆★。RDMA通过网络把数据直接传入计算机的存储区,将数据从一个系统快速移动到远程系统存储器中,实现Zero Copy◆■。
另一类计算刚好和高吞吐计算相反,它们虽然可以给分成若干并行的子任务◆◆■■,但是子任务间联系很紧密◆★★◆★■,需要大量的数据交换。按照Flynn的分类★◆,分布式的高性能计算属于MIMD(Multiple Instruction/Multiple Data★★★★■,多指令流-多数据流)的范畴。
业界还有其他多种测试基准■◆■,有的是基于实际的应用种类如TPC-C◆◆,有的是测试系统的某一部分的性能,如测试硬盘吞吐能力的IOmeter,测试内存带宽的stream。
高性能计算HPC集群中计算节点一般 分3种■◆★★◆: MPI节点、胖节点、GPU加速节点。双路节点称为瘦节点(MPI节点)◆★■★,双路以上称为胖节点◆■◆★◆★;胖节点配置大容量内存;集群中胖节点的数量要根据实际应用需求而定■◆◆★■■。
GPU英文全称Graphic Processing Unit■★,中文翻译为图形处理器。 在浮点运算、并行计算等部分计算方面,GPU可以提供数十倍乃至于上百倍于CPU的性能。目前GPU厂家只有三家NVIDIA GPU、AMD GPU和Intel Xeon PHI★■★★◆■。可选择的GPU种类比较少。
至目前为止, Linpack 还是广泛地应用于解各种数学和工程问题。也由于它高效率的运算, 使得其它几种数学软件例如IMSL、MatLab纷纷加以引用来处理矩阵问题,所以足见其在科学计算上有举足轻重的地位★◆◆■。
有一类高性能计算,可以把它分成若干可以并行的子任务★★◆■◆,而且各个子任务彼此间没有什么关联。因为这种类型应用的一个共同特征是在海量数据上搜索某些特定模式,所以把这类计算称为高吞吐计算★★■◆◆◆。所谓的Internet计算都属于这一类■■■◆◆◆。按照Flynn的分类,高吞吐计算属于SIMDSingle Instruction/Multiple Data,单指令流-多数据流)的范畴。
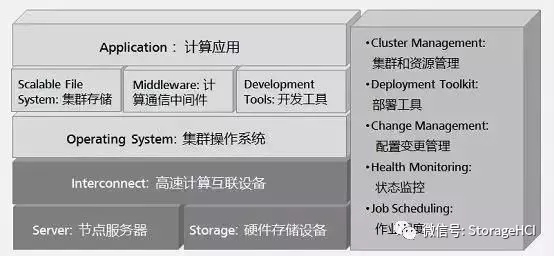
有许多类型的HPC 系统◆★,其范围从标准计算机的大型集群★★■★■★,到高度专用的硬件★■。大多数基于集群的HPC系统使用高性能网络互连,基本的网络拓扑和组织可以使用一个简单的总线拓扑。HPC系统由计算、存储、网络、集群软件四部分组成。
高性能集群在计算过程中,各节点是协同工作的,它们分别处理大问题的一部分◆◆,并在处理中根据需要进行数据交换,各节点的处理结果都是最终结果的一部分。高性能集群的处理能力与集群的规模成正比,是集群内各节点处理能力之和★★■◆■,但这种集群一般没有高可用性。高性能计算的分类方法很多。这里从并行任务间的关系角度来对高性能计算分类★◆。
时延( 内存和磁盘访问延时)是计算的另一个性能衡量指标,在HPC系统中,一般时延要求如下■■■★:





